Transformation of the Transformer
"Attention is all you need" might be the most influential paper in the past decade. The transformer has completely transformed (you can't stop me) AI and is now everywhere.
Naturally, it has also undergone several updates and improvements since its release. And this post is meant to track that.
Timeline: Papers and Models
TBD
Placeholder
Placeholder
When I first looked up mixture of expert models, I was quite confused. Switch transformers had already been around for a really long time!
We are going to organize all the research (and their adoption into open source models) all in one place so we can how things have evolved (...)
...
This is not a beginner's guide, but some useful refreshers and beginner friendly content is inserted in between.
The Base Transformer
Attention is All You Need introduced two key things:
- Scaled Dot Product Attention (which is one of many types of attention, btw)
- Mutli-Head Attention (MHA)
Both of these are components in the "base implementation" of the vanilla transformer. We will therefore use these to establish our context and terms.
Scaled Dot Product Attention
This attention mechanism uses a triplet of matrices: the query matrix , the key matrix , and the value matrix . Each matrix computed by embedding the input token sequence . The output of this attention mechanism is a weighted sum of the value vectors , where the weights are the dot product between the query and key pairings:
In other words, for each pair of and , we get the following "score":
And so for the th input token, we get a vector representing scores of all tokens pairs (that came before*) and can compute a linear combination of all value embeddings for the ith token.
Put another way, this linear combination describes how all the other embeddings are allowed to "infleunce" our token's embedding. Low scores = low influence, high scores = high influence.
It's a dynamic weighing based on the input tokens!
*Notice also that we usually adopt causal attention. i.e. tokens can only be attended to by tokens from before rather than after (no peeking!)
Let's now establish our vocabulary of terms:
| Symbol | Meaning |
|---|---|
| Model size / hidden dimension. | |
| Input sequence embeddings. | |
| Query projection matrix. | |
| Key projection matrix. | |
| Value projection matrix. | |
| Output projection matrix. | |
| Per-head projections (each with width or ). | |
| Query matrix. | |
| Key matrix. | |
| Value matrix. | |
| Row vectors of , , . | |
| Key/value projection dimensions. | |
| Attention weight matrix. | |
| Scaled dot product attention output. | |
| Attention weight from query to key . | |
| Positional encoding matrix. | |
| Positional encoding for token . | |
| Input embedding for token . |
In PyTorch, this mechanism can be written like this:
python
def scaled_dot_product_attention(query, key, value):
# we assume self-attention, and therefore the same source/target lengths
sequence_length = query.size(-2)
# for causal attention, we need a diagonal matrix as a mask
mask = torch.ones(sequence_length, sequence_length).tril(diagonal=0)
bias = (torch
.zeros(sequence_length, sequence_length)
.masked_fill(mask.logical_not(), float("-inf"))
)
scale_factor = 1 / math.sqrt(query.size(-1))
weight = query @ key.transpose(-2, -1) * scale_factor # Q K^T / sqrt(dk)
return torch.softmax(weight + bias, dim=-1) @ value
If you need a refresher or visualisation this section, I strongly recommend this 3blue1brown video:
Multi-Head Attention
To construct a model with dimension , we use multiple scaled dot product attention blocks in parallel, each receiving a chunk of the input with a dimension . This is such that
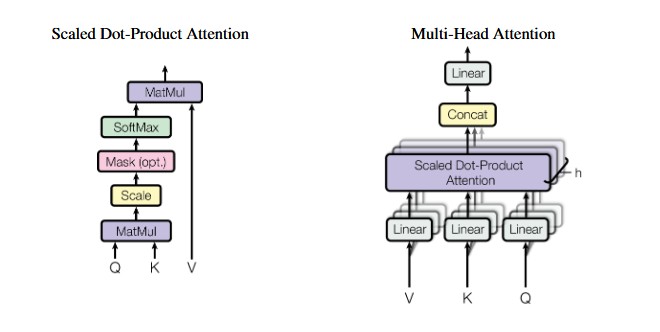
Figure — Transformer model architecture from 'Attention Is All You Need'.
These multiple heads are introduced not to "chunk" the computation into a smaller dimension size (we have other tools for optimizing memory footprint).
Rather, multiple heads are added to allow the model to project the input into multiple independent "representations".
For the sake of refining our intuition, let's explore why we add more heads instead of simply increasing the dimensions of a single head.
Recall that the output of the dot-product between our and query/key vectors is a "score" that looks like this:
This means that no matter the dimensions of and , we obtain a single scalar value for each token and vector pair.
There are hence two ways to intuit this:
- By introducing heads, we decrease compression factor from to , allowing the representation to be richer.
- Each head allows us focus on types of token/vector pair interactions, and hence arrive at unique scores for each variant.
These cannot be achieved by simply increasing
With that, we have the building blocks of the original transformer model.
In this base state, we find that there are a few issues:
- Each of , and require matrix multiplications. Computing attention from these involves another 3 more matrix multiplies (not forgetting the final linear layer). It's expensive to compute.
- Our current attention mechanism is positionally/permutationally invariant. That is, the positions of each token do not matter at all. We simply take a linear combination!
And we can also make it better too!
Hence begins the journey through the years of applying updates to the transformer
KV Caching and Paged Attention
The first big optimization to the attention block comes from the observation that we can "memo-ize" it. For every new input token we add to our sequence, we reuse practically all of the previous and matrices, needing only to add one additional vector.
We therefore cache all cache all "key" and "value" embeddings for all previous tokens during a generation.
But there's a little problem with this...
Memory Management for LLMs inference
Naively, if we were to store each of these key and value embeddings for a generation that can potentially reach tokens in sequence length, then we would have to allocate tokens worth of contiguous memory. This is similar to pre-declaring and allocating memory to the maximum size of our arrays. And most of this could be potentially empty space! Perhaps the user just said "Hello" or "How many Rs are there in strawberry?". That's tokens worth of space for each of these.
This is a large waste of memory during inference where we really can't anticipate memory requirements.
Enter paged attention. Instead of a contiguous block of memory for the KV cache, we chunk them into blocks. And then track each block using a block table. This block table is a mapping between token id series and memory addresses.
This means a few things:
- Blocks need not be contiguous. We piece them together when needed. And only allocate memory when needed.
- We can share blocks between queries. This is especially useful for constantly reused system prompts and other patterns of tokens. Blocks are a look up of token ids!
All of this translates to memory savings!
Grouped Query Attention
In Fast Transformer Decoding: One Write-Head is All You Need we take our memory savings further.
Instead of storing heads worth of KV caches, we group the heads into groups and have each group share a set of KV tensors. Hence, we slash memory by a factor of , i.e. the number of heads assigned to a group.
Multi-Head Latent Attention
Breaking away from the chronological progression... Multi-Head Latent Attention is a natural progression (and huge upgrade) from Grouped Query Attention.
Rotary Postion Embeddings (RoPE)
To deal with the issue of our attention mechanism being positionally invariant, we introduce the idea of positional embeddings into our transformer.